Swift 解读
SWIFT 文章解读,详细.
资料来源:
https://vanbever.eu/pdfs/vanbever_swift_sigcomm_2017.pdf
更新
1
20.10.29 初稿完成
导语
SWIFT 文章解读,结果被告知超过 2h 没得出大意就换,我这早就弄出来了,最后才说…😓…
解读
论文试图解决什么问题?
- AS 之间 bgp 收敛缓慢,导致的网络中断.
为什么 bgp 收敛缓慢?
- 因为 AS 域间策略,隐私性等,路由系统隐藏了 AS 的路由拓扑和路由策略,导致无法得知备份路径.
- 任何路由信息是以前缀为基础通告的,导致没办法一次性重路由大量前缀.
- 当然还有最小路由通告间隔等等,文章没有详细分析.
现状?
- 文章分析了真实的 bgp 数据,指出网络经常出现类似的突发事件.
- 数据集:3335 次.10s 大部分会收敛,39%(1239) > 10s,9.7%(314) > 30s.
swift 试图做什么?
- 快速预测故障链路 -> 推理算法,只根据很少的 bgp 信息,几秒内快速推理
- 快速重定向受影响的流量 -> swift 编码规则,近乎一次性重定向所有受影响流量,一次性重定向与前缀数量无关.
swift
- 推理算法
- 推理的准确定位和 bgp 信息成正比,信息不足,就无法准确定位.
- swift 推理算法采用了保守策略,牺牲了准确定位,只根据少量 bgp 信息,快速给出一组最可能包含故障链路的超集.
- 模拟和实际测试表明,快速返回的结果,几乎都包含了故障链路,或者在故障链路的旁边.
- 编码规则
- bgp 重定向根据前缀来,太慢.
- 对每个进入部署 swift AS 的数据包打标签 (目的地 mac 地址)
- 标签包括数据包接下来的正常 AS 路径,和每一跳的备份路径.
- 重定向以链路为筛选而不是前缀,一次性快速重定向大量流量到实现计算好的备份下一跳.
- 重定向采用保守策略,会选择尽可能绕过推理算法返回的链路集合 (绕过所有与推理故障链路集有关或相邻的公共端点)
- 推理的结果可能不是最佳的,重定向的临时路径可能不是最佳的,但是两个保守加一块,就能做到快速重定向受影响的流量,保证网络不会中断.
- swift 不会影响 bgp
- 标签选择了数据包的目的地 mac,当数据包离开部署 swift 的 AS 时会重新填入正确的目的地 mac,相当于删除标签.
- swift 重定向规则,只对 AS 内部生效,bgp 正常收敛后,重定向规则会被删除.
Bgp 收敛示例

说明:
- 每一个都是不同的 AS.
- swift 部署在 AS1.
- 故障在 链路 (5,6)
- k 代表 AS 的前缀数量
- 假设所有 AS 都部署了快速重路由技术.(与现状相反)
故障:
- AS5 事先知道 AS3 有一条到 AS7 的备份路径.(5,6) 故障后到 立刻切换到备份路径,AS7 的 10K 前缀路径更新.
- AS5 不知道到 AS6 AS8 的备份路径,发布 11k 的路径撤销,表明到 AS6 AS8 不通.
- 最后 AS5 通过 AS2 才恢复了到 AS6 AS8 的连接.
推理算法
首先我们假定只有一条故障链路.(上一节的情况)
推理算法使用 Fit Score (FS) 的值作为推理链路故障的依据,FS 越大,链路故障的可能性越高.
前置
- 以 t 作为返回推理的时间,任何一个链路 l.
参数
- $W(t)$ 是截至 t 时刻,收到的被撤回的总数量.
- $W(l,t)$ 路径包括 l 且在 t 时刻被撤回前缀的数量.
- $P(l,t)$ 是截至 t 时刻,变化后的新生成路径仍然包括路径 l 的前缀数量.
WS 指的是在 t 时间,路径包括链路 l 的被撤销前缀 占 所有被撤销前缀的比例.越接近 1 断路可能性越高.
$$WS(l,t) = \frac{W(l,t)}{W(t)}$$
PS 是 t 时间,路径包括链路 l 的被撤销前缀 占 变化路径包括 l 的前缀的比例 (变化是指撤销和新生成的路径).越接近 1 断路可能性越高
$$PS(l,t) = \frac{W(l,t)}{W(l,t) + P(l,t)}$$
对 l 而言其 FS 值为 Withdrawal Share (WS) 和 Path Share (PS) 的加权几何平均值.
$$FS(l,t) = (WS(l,t)^{w_{WS}} * PS(l,t)^{w_{PS}})^{1/(w_{WS} + w_{PS})}$$
- $w_{WS}$ 和 $w_{PS}$ 是我们分配给 WS 和 PS 的权重.(下文会提到)
原文:
WS is the fraction of prefixes forwarded over l that have been
withdrawn at t over all the received withdrawals.
PS is the fraction of withdrawn prefixes with a path via l at t over the prefixes with a path via l at t.
where W (l,t) is the number of prefixes whose paths include l and have been withdrawn at t
W (t) is the total number of withdrawals received as of t;
P(l,t) is the number of prefixes whose paths still
traverse l at t.
推理算法示例

如图是示例 (5,6) 链路断路后,WS 和 PS 的值.
- 上文可以知道,有 11k 前缀被撤销,所以 $W(t) = 11k$
- 链路 (5,6)
- WS: 所有撤销都与 (5,6) 有关,所以 WS = 1.
- PS: 新生成的路径肯定都不包括 (5,6),所以 $P(56,t) = 0$,所以 PS = 1.
- 链路 (1,2)
- WS: 通过流量图 (a) 可以看出来,AS1 到 AS6 AS8 的链路全经过 (5,6),(5,6) 断路,原本的路径全部需要撤销,所以 $W(12,t) = 11$,WS = 1
- PS: 流量图 (b) 新生成的路径中,AS5 和 AS2 的全部前缀都走 (1,2),各有 1k 前缀,所以 $PS(12,t) = 2$,所以 PS = 11/13
- 链路 (2,5): 与链路 (1,2) 推算非常类似
- WS: WS = 1
- PS: PS = 11/12
- 链路 (6,7),到 AS7 的 10k 前缀在 (6,7) 没有受到影响.
- WS = 0
- PS = 0
- 链路 (6,8)
- WS: AS6 有 1k 前缀,所以撤销的前缀中与 (6,8) 有关的,只有 10k.所以 $W(68,t) = 10$,所以 WS = 10/11.
- PS: 与 (6,7) 类似,到 AS8 的 10k 前缀在 (6,8) 没有受到任何影响,$PS(68,t) = 0$,PS = 10/10 = 1
WS PS 权重
原文:
Contrary to the assumptions of Theorem 4.1, SWIFT runs its inference algorithm at the beginning of a burst. Lack of information (i.e., carried by not yet received withdrawals) can therefore affect its accuracy. Being aware of this lack of information, SWIFT uses different weights for WS and PS in the geometric mean calculated in the fit score FS (see §4.1).
The key intuition is that early on during the burst, a large number prefixes are not yet withdrawn and are still using the failed link. As a result, the PS for that link may not be the highest one. The PS for the failed link actually increases when SWIFT runs the inference later in the burst.
However, the WS for the failed link will always be greater or equal than the WS of any other link, provided that SWIFT does not receive unrelated withdrawals and that the outage is produced by a single link failure. SWIFT thus performs better when wW S > wP S .
原因:
- 故障发生后早期,大量链路撤销通告还没有收到,大量前缀仍然在使用中断的链路.结果就是故障链路的 PS 值可能不是最高的,在开始推理算法后,其 PS 值可能还会升高.
- 但是故障链路的 WS 值一直是 >= 其他链路.
因此为了尽早返回推理结果,直觉上,计算 FS 时 WS 的权重要大于 PS.使用 bgp 数据测试,发现 $w_{WS}$ 比 $w_{PS}$ 大 3 倍时,swift 性能最好.
推理算法策略
上文说到了,如果无法区分具体那一个链路故障,swift 采用保守策略,直接返回全部可能故障的链路集合.
上文的例子中,swift 无法区分 (5,6) 和 (6,8),最后全部返回.
推理算法并发
多条链路链接到同一个路由器,路由器故障会导致多条链路中断.
推理算法计算共享一个端点的一组链路集合的 FS 值,把有共同端点的链路按照 FS 从大到小聚合起来,直到链路集合的 FS 值不再增加.
通过拓展 WS 和 PS 的定义,可以对任意一组链路 S 的拟合计算 FS 值.
$$WS(S,t) = \frac{\sum_{l \varepsilon S}{W(l,t)}}{W(t)}$$
$$PS(S,t) = \frac{\sum_{l \varepsilon S}{W(l,t)}}{\sum_{l \varepsilon S}{W(l,t)+P(l,t)}}$$
最后算法返回具有最高 FS 的链路集合 (可能只有单条链路).
推理算法启动/返回
这里的参数依旧是从实际 bgp 数据测试推导而来.
swift 使用正在进行突发事件钟撤回总数,有一个触发阈值,当收到的撤回数量超过时启动推理算法.同时与历史数据做对比,如果通过历史数据得出发送突发情况的概率很高,则立刻返回.否则继续等待一个固定数量再返回.
具体而言如下:
- 收到 2.5k 撤回,启动推理算法.
- 2.5k/10k 返回
- 5k/20k 返回
- 7.5k/50k 返回
- 10k/100k 返回
- 超过 20k 撤回立刻返回.
这里的预测撤回数,指的是预测受影响的前缀总数? 还是 swifted 路由中已经编码的前缀总数??
原文:
SWIFT uses the number of withdrawals in an ongoing burst as an estimation of the carried information. It launches a first inference after a fixed number of withdrawals, which we call triggering threshold. If the likelihood of seeing an inferred burst of that size is high enough with respect to historical data, then it returns the inferred link. Otherwise, it waits for another fixed number of withdrawals, and iterates(迭代?).
Using real BGP bursts as baseline (see [33]), we set the default values of the triggering threshold to 2.5k withdrawals.
Also, SWIFT returns the inferred link if the number of predicted withdrawals is less than 10k for 2.5k received withdrawals, 20k for 5k received, 50k for 7.5k received, and 100k for 10k received. After having received 20k withdrawals, SWIFT returns the inferred linkregardless of the number of predicted prefixes.
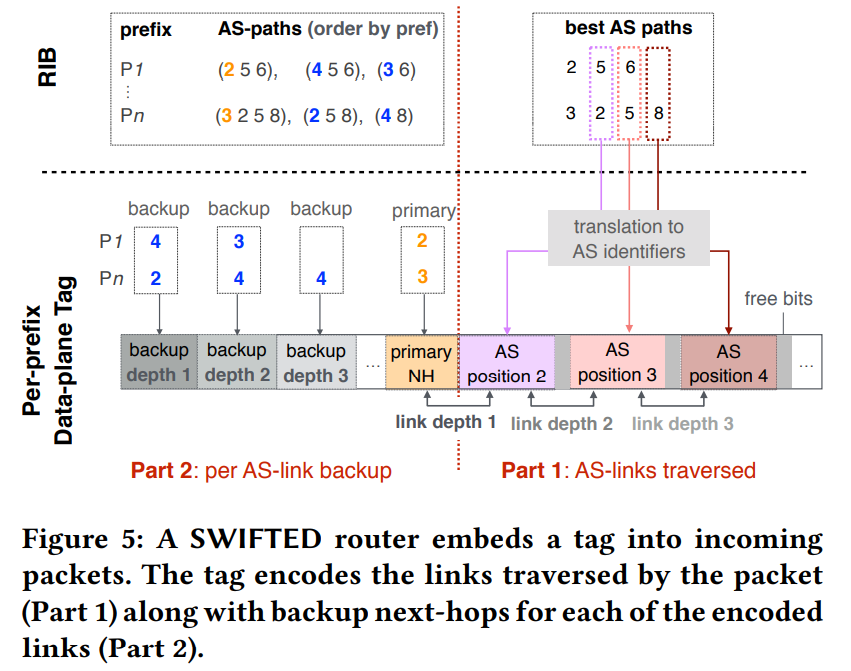
编码规则 (还有坑)
标签
- 第一部分: 正常情况下数据包的 AS 路径.按照 AS-path 顺序 (除了第一位) 写入 AS 唯一标识符.两个 AS 标识符相邻即一条路径.
- 第二部分: 各条链路的备份下一跳.第一位: 主下一跳 (与备份无关),第二位是 as-path 第一条链路备份下一跳,..
长度分配
使用的是数据包的目的地 mac 总共有 48 bit.
两部分的长度平衡
- as-path 长,则可以覆盖更远的故障
- 备份路径更长,则可以提供更多的备份路径选择
- 全球互联网的 AS 超过了 600k,不可能对所有 AS 编号.
as-path
- 忽略少于 1500 前缀的链路 (影响不大,很容易解决)
- 只编码 AS 路径的前 5 跳.(再远的话,中间节点可能知道备份路径)
- swift 只对已经在 bgp 路径中存在的 AS 链路和位置进行编码.
原文第 6 节的实验数据表明,18 个比特位足够覆盖 98% 可能受影响的前缀.
AS 路径
具体步骤:
- 取备选路径最长长度 m,定义一个容量 m 的 set
- 取 bset 路径 $(u_0 u_1 … u_k)$,swift 对每个 AS 都有一个唯一的编码.将 $(u_1 … u_k)$ 转化成 AS 唯一标识符按照顺序写入 set.
- 注意上面没有对 $u_0$ 编号,第一跳标识为了标签第二部分的主下一跳.
- 具体某个 AS 占几位,自适应.
- 同一个 AS 在不同 AS-path 不同位置,标识符也可能不同.
备份下一跳 (推算还是有疑问)
分配给 as-path 18 位,备份下一跳可以有 30 位.
swifted 深度 4(as-path 5 跳),备份下一跳 (1+4),每个位置有 $2^6 = 64$.深度 3(as-path 4 跳),备份下一跳 (1+3),每个位置有 $2^7 = 128$.还有两位空闲再分给 as-path.
运营商可以根据实际情况自行调整.
swift 支持重路由策略.在计算下一跳时,swift 可以计算符合运营商指定的重路由策略的下一跳
swift 支持本地和远程的备份下一跳,swifted 路由器可以使用隧道 (IP 或者 MPLS 等) 还可以快速重定到远程下一跳,远程备份下一跳是通过普通的 ibgp 会话学习的.
编码示例
工作流
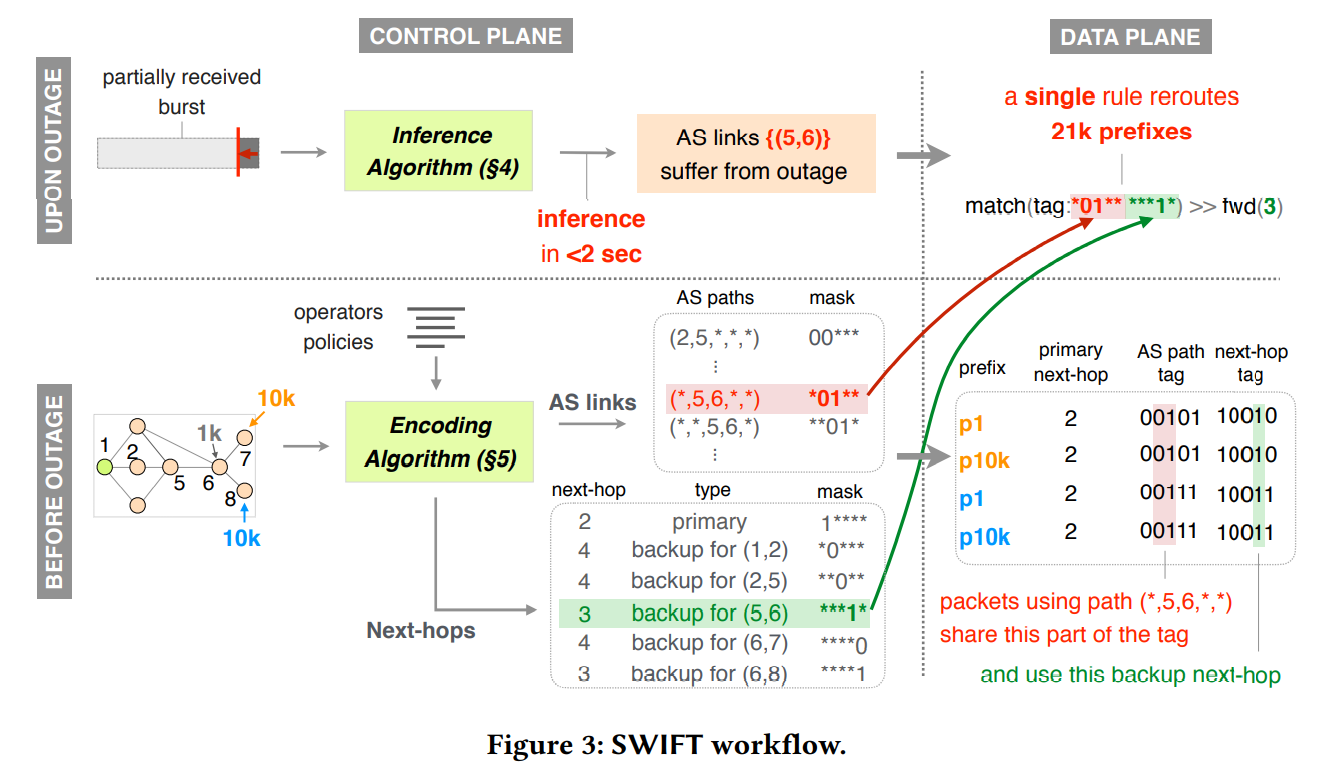
原文第 3 节的一个工作流.siwft 部署在 AS1.
AS-path 编码
as-path:
- 1 2 5 (1k)
- 1 2 5 6 (1k)
- 1 2 5 6 7 (10k)
- 1 2 5 6 8 (10k)
编码:
- 第 1 位不编码,从第 2 位开始编码.
- 则前两位是都各自只有 1 个 AS,则 0,0 即可表示.
- 第 3 位,有 AS6, x 两种,则取 AS6 标识为 1
- 第 4 位,有 AS7 AS8 两种,取 AS7 标识为 0,AS8 标识为 1.
- 第 5 位,全部都是 x..(这里和网络拓扑有关,原文提到了取得是 5 跳),全 1.
所以链路 (1,2,5,6,8) 对应 as-path 编码 00111.
备份下一跳
- 怎么算的,没有跟这张图对应起来.
编码:
- 第 1 位: 主下一跳是 AS1
- 第 2 位: 主备份下一跳 (链路 (1,2) 的备份下一跳) AS2
- 第 3 位: 链路 (2,5) 备份下一跳 AS4
- 第 4 位: 链路 (5,6) 备份下一跳 AS3
链路 (1,2,5,6,8) 的备份下一跳编码: 10010
所以对所有到 AS8 的数据包有
1 | match(dst_prefix:in AS8) >> set(tag:00111 10011) |
重定向流量
在 链路 (5,6) 故障以前有
1 | match(tag:***** 1****) >> fwd(2) |
全部第 2 跳走链路 (5,6) 的数据包,重定向到预先选择的备份路径 (AS3).
1 | match(tag:*01** ***1*) >> fwd(3) |
评估
原文第 6 节.